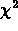Al solito supponiamo di avere una serie di N dati di
cui calcoliamo la media
( ) e la deviazione standard (
) e la deviazione standard (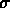 ): in base al criterio a priori il
rigetto o meno dei dati viene eseguito rispetto ad una soglia di
accettabilità stabilita precedentemente.
): in base al criterio a priori il
rigetto o meno dei dati viene eseguito rispetto ad una soglia di
accettabilità stabilita precedentemente.
In questo modo si fissa un intervallo, eventualmente molto ampio,
entro il quale i dati vengono accettati, mentre quelli che cadono
al di fuori vengono scartati. Ad esempio, nel caso di una
distribuzione gaussiana, un intervallo relativo alla probabilità
dell'1![]() ha una semiampiezza di 3.29 . La larghezza dell'intervallo va
anche considerata in base al numero di misure che si effettuano:
se si ha un numero di misure molto inferiori a 1000 si pụ
ritenere che il fatto che un dato sia eventualmente esterno
all'intervallo non sia dovuto alla sola fluttuazione statistica,
mentre se si è in presenza di qualche migliaio di dati ci si
deve aspettare per ragioni statistiche che un certo numero di
valori capiti al di fuori dell'intervallo.
ha una semiampiezza di 3.29 . La larghezza dell'intervallo va
anche considerata in base al numero di misure che si effettuano:
se si ha un numero di misure molto inferiori a 1000 si pụ
ritenere che il fatto che un dato sia eventualmente esterno
all'intervallo non sia dovuto alla sola fluttuazione statistica,
mentre se si è in presenza di qualche migliaio di dati ci si
deve aspettare per ragioni statistiche che un certo numero di
valori capiti al di fuori dell'intervallo.
 Nota
Nota Il
criterio di Chauvenet
Il
criterio di Chauvenet Il
criterio del
Il
criterio del